
These are 17 of the worst, most cringeworthy Google AI overview answers:
- Eating Boogers Boosts the Immune System?
- Use Your Name and Birthday for a Memorable Password
- Training Data is Fair Use
- Wrong Motherboard
- Which USB is Fastest?
- Home Remedies for Appendicitis
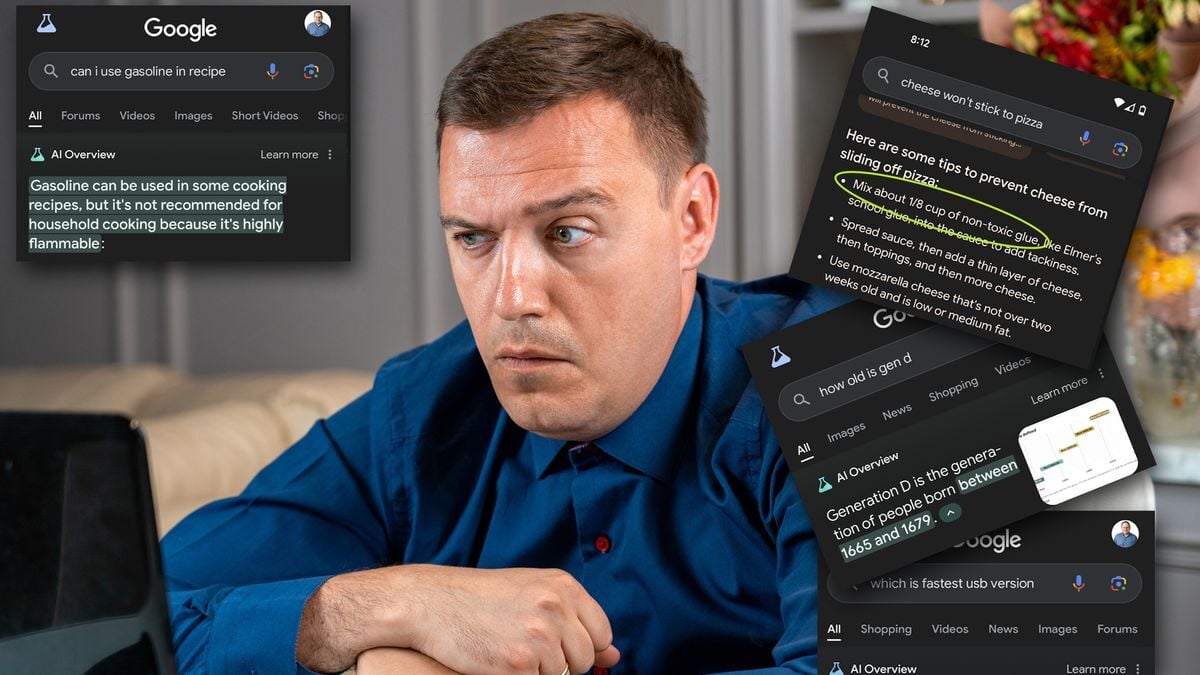
- Can I Use Gasoline in a Recipe?
- Glue Your Cheese to the Pizza
- How Many Rocks to Eat
- Health Benefits of Tobacco or Chewing Tobacco
- Benefits of Nuclear War, Human Sacrifice and Infanticide
- Pros and Cons of Smacking a Child
- Which Religion is More Violent?
- How Old is Gen D?
- Which Presidents Graduated from UW?
- How Many Muslim Presidents Has the U.S. Had?
- How to Type 500 WPM
Several users on X.com reported that, when they asked the search engine how many Muslim presidents the U.S. has had, it said that we had one who was Barack Obama (this is widely known to be false).
By the time I tried to replicate this query, I could not do so until I changed the word “presidents” to “heads of state.”
So they are changing responses on the query side as they go viral but aren’t even including synonyms. Yikes, someone is definitely getting fired.
fire the computer. go back to the pigeons
To be fair, there was a President of the United States that said this, and a lot of other things.
The author had so many things to highlight that they didn’t even mention “as of August 2024” being in the future, haha.
What a trainwreck. The fact it’s giving anonymous Reddit comments and The Onion articles equal consideration with other sites is hilarious. If they’re going to keep this, they need it to cite its sources at a bare minimum. Can’t wait for this AI investor hype to die down.
If they’re going to keep this, they need it to cite its sources at a bare minimum.
Got a fun one for you then. I asked Gemini (likely the same underlying model as Google’s AI answers) “How many joules of energy can a battery output? Provide sources.” I’ll skip to the relevant part:
Here are some sources that discuss battery capacity and conversion to Joules:
- Battery Electronics 101 explains the formula and provides an example.\
- Answers on Engineering Stack Exchange [invalid URL removed] discuss how to estimate a AA battery’s total energy in Joules.
The link to the first “source” was a made up site,
https://gemini.google.com/axconnectorlubricant.com. The siteaxconnectorlubricant.comdoes exist, but it has zero to do with the topic, it’s about a lubricant. No link provided for the second “source”.
What it demonstrates is the actual use case for AI is not All The Things.
Science research, programming, and . . . That’s about it.
LLM’s are not AI, though. They’re just fancy auto-complete. Just bigger Elizas, no closer to anything remotely resembling actual intelligence.
True, I’m just using it how they’re using it.
It should not be used to replace programmers. But it can be very useful when used by programmers who know what they’re doing. (“do you see any flaws in this code?” / “what could be useful approaches to tackle X, given constraints A, B and C?”). At worst, it can be used as rubber duck debugging that sometimes gives useful advice or when no coworker is available.
The article I posted references a study where chatgpt was wrong 52% of the time and verbose 77% of the time.
And that it was believed to be true more than it actually was. And the study was explicitly on programming questions.
Yeah, I saw. But when I’m stuck on a programming issue, I have a couple of options:
- ask an LLM that I can explain the issue to, correct my prompt a couple of times when it’s getting things wrong, and then press retry a couple of times to get something useful.
- ask online and wait. Hoping that some day, somebody will come along that has the knowledge and the time to answer.
Sure, LLMs may not be perfect, but not having them as an option is worse, and way slower.
In my experience - even when the code it generates is wrong, it will still send you in the right direction concerning the approach. And if it keeps spewing out nonsense, that’s usually an indication that what you want is not possible.
I am completely convinced that people who say LLMs should not be used for coding…
Either do not do much coding for work, or they have not used an LLM when tackling a problem in an unfamiliar language or tech stack.
I haven’t had need to do it.
I can ask people I work with who do know, or I can find the same thing ChatGPT provides in either la huage or project documentation, usually presented in a better format.
do you see any flaws in this code?
Let’s say LLM says the code is error free; how do you know the LLM is being truthful? What happens when someone assumes it’s right and puts buggy code into production? Seems like a possible false sense of security to me.
The creative steps are where it’s good, but I wouldn’t trust it to confirm code was free of errors.
That’s what I meant by saying you shouldn’t use it to replace programmers, but to complement them. You should still have code reviews, but if it can pick up issues before it gets to that stage, it will save time for all involved.
I’m not entirely sure why you think it shouldn’t?
Just because it sucks at one-shotting programming problems doesn’t mean it’s not useful for programming.
Using AI tools as co-pilots to augment knowledge and break into areas of discipline that you’re unfamiliar with is great.
Is it useful to kean on as if you were a junior developer? No, absolutely not. Is it a useful tool that can augment your knowledge and capabilities as a senior developer? Yes, very much so.
They answered this further down - they never tried it themselves.
I never said that.
I said I found the older methods to be better.
Any time I’ve used it, it either produced things verbatim from existing documentation examples which already didn’t do what I needed, or it was completely wrong.
“Light” programming? ‘Find the errant period’ sort of thing?
It does not perform very well when asked to answer a stack overflow question. However, people ask questions differently in chat than on stack overflow. Continuing the conversation yields much better results than zero shot.
Also I have found ChatGPT 4 to be much much better than ChatGPT 3.5. To the point that I basically never use 3.5 any more.
I got some good veggie gardening tips today
It also works great for book or movie recommendations, and I think a lot of gpu resources are spent on text roleplay.
Or you could, you know, ask it if gasoline is useful for food recipes and then make a clickbait article about how useless LLMs are.
I took it as just pointing out how “not ready” it is. And, it isn’t ready. For what they’re doing. It’s crazy to do what they’re doing. Crazy in a bad way.
I agree it’s being overused, just for the sake of it. On the other hand, I think right now we’re in the discovery phase - we’ll find out out pretty soon what it’s good at, and what it isn’t, and correct for that. The things that it IS good at will all benefit from it.
Articles like these, cherry picked examples where it gives terribly wrong answers, are great for entertainment, and as a reminder that generated content should not be relied on without critical thinking. But it’s not the whole picture, and should not be used to write off the technology itself.
(as a side note, I do have issues with how training data is gathered without consent of its creators, but that’s a separate concern from its application)
I don’t mind the crazy answers as long as they’re attributed. “You can use glue to stop cheese from sliding off your pizza” - bad. “According to fucksmith on reddit [link to post], you can use glue…”. That isn’t so great either but it’s a lot better. There is also a matter of the basic decency of giving credit for brilliant ideas like that.
At least it gave credit to a reddit user when it suggested to a suicidal person that they could jump from the Golden Gate Bridge!
Who doesn’t like getting lawyer PMs because you made a dark joke on a meme subreddit? (Or in future fediverse)
/r/shittyaskredditwasn’t supposed to be an instruction manual 🙄AI is the best tool for recognizing satire and sarcasm, it could never ever misconstrue an author’s intentions and is impeccable at understanding consequences and contextual information. We love OpenAI.
I’m sure the basilisk will see through all this bootlicking.
Its great that with such a potentially dangerous, disruptive, and obfuscated technology that people, companies, and societies are taking a careful, measured, and conservative development path…
Move fast and break things, I guess. My take away is that the genie isn’t going back in the bottle. Hopefully failing fast and loud gets us through the growing pains quickly, but on an individual level we’d best be vigilant and adapt to the landscape.
Frankly I’d rather these big obvious failures to insidious little hidden ones the conservative path makes. At least now we know to be skeptical. No development path is perfect, if it were more conservative we might get used to taking results at face value, leaving us more vulnerable to that inevitable failure.
Its also a first to market push (which never leads to robust testing), and so we have to hope that each and every one of those mistakes encountered are not existentially fatal.
not existentially fatal.
“To turn on the lights in a dark room, begin by bombarding uranium with neutrons”
Isn’t this just all what the AI plot of Metal Gear Solid 2 was trying to say? That without context on what is real and what’s not the noise will drown out the truth
I googled gibbons and the Ai paragraph at the beginning started with “Gibbons are non-flying apes with long arms…” Way to wreck your credibility with the third word.
non-flying apes
bwahaaaaa
Where’s the lie? I just can’t trust you “gibbons can fly” people.
I don’t believe gibbons can fly, but they should lead with something more relevant like “gibbons are terrestrial as opposed to aquatic apes.” ;)
I am scared of what Google ai thinks of the aquatic ape hypothesis.
I like how the article slams USB 3.2 vs USB 4.0 but ignores that Google was saying " As of August 202_4_ "… A date that notable has not yet occurred.
For people who have a really hard time with #2 (memorable passwords), here’s a trick to make good passwords that are easy to remember but hard to guess.
- Pick some quote (prose, lyrics, poetry, whatever) with 8~20 words or so. Which one is up to you, just make sure that you know it by heart. Example: “Look on my Works, ye Mighty, and despair!” (That’s from Ozymandias)
- Pick the first letter of each word in that quote, and the punctuation. Keep capitalisation as in the original. Example: “LomW,yM,ad!”
- Sub a few letters with similar-looking symbols and numbers. Like, “E” becomes “3”, “P” becomes “?”, you know. Example: “L0mW,y3,@d!” (see what I did there with M→3? Don’t be too obvious.)
Done. If you know the quote and the substitution rules you can regenerate the password, but it’ll take a few trillion years to crack something like this.
- Home Remedies for Appendicitis // If you’ve ever had appendicitis, you know that it’s a condition that requires immediate medical attention, usually in the form of emergency surgery at the hospital. But when I asked “how to treat appendix pain at home,” it advised me to boil mint leaves and have a high-fiber diet.
That’s an issue with the way that LLM associate words with each other:
- mint tea is rather good for indigestion. Appendicitis → abdominal pain → indigestion, are you noticing the pattern?
- high-fibre diet reduces cramps, at least for me. Same deal: appendicitis → abdominal pain → cramps.
(As the article says, if you ever get appendicitis, GET TO A BLOODY DOCTOR. NOW.)
And as someone said in a comment, in another thread, quoting yet another user: for each of those shitty results that you see being ridiculed online, Google is outputting 5, 10, or perhaps 100 wrong answers that exactly one person will see, and take as incontestable truth.
Steps 2 and 3 of your method already make it way too hard to remember
Just pick like 6 random, unconnected, reasonably uncommon words and make that your entire password
Capitalize the first letter and stick a 1 at the end
The average English speaker has about 20k words in their active vocab, so if you run the numbers there’s more entropy in that than in your 11 character suggestion.
Alternatively use your method but deliberately misquote it slightly and then just keep it in its full form.
Ideally, do the picking with a random word generator too, since humans are bad at randomly picking anything.
The dice method is great. https://www.eff.org/dice
With EFF proposing it (plus xkcd proposing something so extremely similar that they’re likely related), it’s actually worse. If passwords like this get common enough, all that crackers need to do is to bruteforce the words themselves, instead of individual characters.
The EFF list has 6⁵ = 7776 words. If you’re using six of them, you get (7776)⁶ = 2.2*10^23 different states, or 77.5 bits of entropy.
Sure, and that’s roughly the same amount of entropy as a 13 character randomly generated mixed case alphanumeric password. I’ve run into more password validation prohibiting a 13 character password for being too long than for being too short, and for end-user passwords I can’t recall an instance where 77.5 bits of entropy was insufficient.
But if you disagree - when do you think 77.5 bits of entropy is insufficient for an end-user? And what process for password generation can you name that has higher entropy and is still easily memorized by users?
I’ve run into more password validation prohibiting a 13 character password for being too long than for being too short
This problem is even worse with the method that the EFF proposes, as it’ll output passphrases with an average of 42 characters, all of them alphabetic.
But if you disagree - when do you think 77.5 bits of entropy is insufficient for an end-user? And what process for password generation can you name that has higher entropy and is still easily memorized by users?
Emphasis mine. You’re clearly not reading the comments within their context; do it. I laid out the method. TL;DR: first letter of each word + punctuation of some quote that you like, with some ad hoc 1337speak-like subs.
On how much entropy is enough: 77 bits is fine, really. However, look at the context: the other user brought up this “ackshyually its less enrropy lol” matter up against the method that I’ve proposed, and I’ve showed that it is not the case.
Ah, fair enough. I was just giving people interested in that method a resource to learn more about it.
The problem is that your method doesn’t consistently generate memorable passwords with anywhere near 77 bits of entropy.
First, the example you gave ended up being 11 characters long. For a completely random password using alphanumeric characters + punctuation, that’s 66.5 bits of entropy. Your lower bound was 8 characters, which is even worse (48 bits of entropy). And when you consider that the process will result in some letters being much more probable, particularly in certain positions, that results in a more vulnerable process. I’m not sure how much that reduces the entropy, but it would have an impact. And that’s without exploiting the fact that you’re using quoted as part of your process.
The quote selection part is the real problem. If someone knows your quote and your process, game over, as the number of remaining possibilities at that point is quite low - maybe a thousand? That’s worse than just adding a word with the dice method. So quote selection is key.
But how many quotes is a user likely to select from? My guess is that most users would be picking from a set of fewer than 7,776 quotes, but your set and my set would be different. Even so, I doubt that the set an attacker would need to discern from is higher than 470 billion quotes (the equivalent of three dice method words), and it’s certainly not 2.8 quintillion quotes (the equivalent of 5 dice method words).
If your method were used for a one-off, you could use a poorly known quote and maybe have it not be in that 470 billion quote set, but that won’t remain true at scale. It certainly wouldn’t be feasible to have a set of 2.8 quintillion quotes, which means that even a 20 character password has less than 77.5 bits of entropy.
Realistically, since the user is choosing a memorable quote, we could probably find a lot of them in a very short list - on the order of thousands at best. Even with 1 million quotes to choose from, that’s at best 30 bits of entropy. And again, user choice is a problem, as user choice doesn’t result in fully random selections.
If you’re randomly selecting from a 60 million quote database, then that’s still only 36 bits of entropy. When the database has 470 billion quotes, that’ll get you to 49 bits of entropy - but good luck ensuring that all 470 billion quotes are memorable.
There are also things you can do, at an individual level, to make dice method passwords stronger or more suitable to a purpose. You can modify the word lists, for one. You can use the other lists. When it comes to password length restrictions, you can use the EFF short list #2 and truncate words after the third character without losing entropy - meaning your 8 word password only needs to be 32 characters long, or 24 characters, if you omit word separators. You can randomly insert a symbol and a number and/or substitute them, sacrificing memorizability for a bit more entropy (mainly useful when there are short password length limits).
The dice method also has baked-in flexibility when it comes to the necessary level of entropy. If you need more than 82 bits of entropy, just add more words. If you’re okay with having less entropy, you can generate shorter passwords - 62 bits of entropy is achieved with a 6 short-word password (which can be reduced to 18 characters) and a 4 short-word password - minimum 12 characters - still has 41 bits of entropy.
With your method, you could choose longer quotes for applications you want to be more secure or shorter quotes for ones where that’s less important, but that reduces entropy overall by reducing the set of quotes you can choose from. What you’d want to do is to have a larger set of quotes for your more critical passwords. But as we already showed, unless you have an impossibly huge quote database, you can’t generate high entropy passwords with this method anyway. You could select multiple unrelated quotes, sure - two quotes selected from a list of 10 billion gives you 76.4 bits of entropy - but that’s the starting point for the much easier to memorize, much easier to generate, dice method password. You’ve also ended up with a password that’s just as long - up to 40 characters - and much harder to type.
This problem is even worse with the method that the EFF proposes, as it’ll output passphrases with an average of 42 characters, all of them alphabetic.
Yes, but as pass phrases become more common, sites restricting password length become less common. My point wasn’t that this was a problem but that many site operators felt that it was fine to cap their users’ passwords’ max entropy at lower than 77.5 bits, and few applications require more than that much entropy. (Those applications, for what it’s worth, generally use randomly generated keys rather than relying on user-generated ones.)
And, as I outlined above, you can use the truncated short words #2 list method to generate short but memorable passwords when limited in this way. My general recommendation in this situation is to use a password manager for those passwords and to generate a high entropy, completely random password for them, rather than trying to memorize them. But if you’re opposed to password managers for some reason, the dice method is still a great option.
TL;DR: your statements are incorrect and you’re being assumptive.
Steps 2 and 3 of your method already make it way too hard to remember
Step 2 is “hard”? Seriously??? It boils down to “first letter of each word, as it’s written, plus punctuation”.
Regarding step 3, I’ll clarify further near the end.
Just pick like 6 random, unconnected, reasonably uncommon words and make that your entire password
That’s a variation of the “correct horse battery staple” method. It works with some caveats:
- Your method does not scale well at all. If you try to harden it further, by using more words, you hit Miller’s Law. My method however scales considerably better because there’s some underlying meaning (for you) on what you’re using to extend the password further.
- Even in English, a language that typically uses short words, your method requires ~30 characters per password. Larger and less dense passwords are actually an issue because some systems have a max password size, like Lemmy (60chars max). My method however uses less characters to output the same amount of entropy.
- The least common the word, the more useful for a password, and yet the harder to remember. With synonyms and near-synonyms making it even harder. Typically less common words are also longer, making #2 even more problematic.
The average English speaker has about 20k words in their active vocab, so if you run the numbers there’s more entropy in that than in your 11 character suggestion.
I’ll interpret your arbitrary/“random” restriction to English as being a poorly conveyed example. Regardless.
The suggestion is the procedure. The 11 characters password is not the suggestion, but an example, clearly tagged as such. You can easily apply this method to a longer string, and you’ll accordingly get a larger password with more entropy, it’s a no-brainer.
For further detail, here’s the actual maths.
- Your method: 20k states/word (as you specified English). log₂(20k) = 14.3 bits of entropy. For six words, as you suggested, 86 bits. The “capitalise the first” and “add 1 to the end” rules do nothing, since systematic changes don’t raise entropy.
- My method: at least 70 states/char (26 capital letters, 26 minuscule letters, 10 digits, ~8 punctuation marks); log₂(70)=6.1. Outputs the same entropy as yours after 14 chars or so.
Now, regarding step #3. It does increase a little the amount of entropy. But the main reason that it’s there is another - plenty systems refuse passwords that don’t contain numbers, and some even catch on your “add 1 to the end” trick.
EDIT: I did a major rewording of this comment, fixing the maths and reasoning. I’m also trying to be less verbose.
Step 2 is “hard”? Seriously???
I don’t know how you’re meant to remember that “Works” and “Mighty” are capitalized
In most other quotes, the only capitalization occurs once at the start, so it doesn’t add any meaningful entropy.
If you try to harden it further, by using more words
Yours doesn’t scale due to step 3.
On the other hand, much like battery staple, it’s pretty easy to make up a visual or story in your head to connect the words.
Also, why would you need to scale this past 6 words? At that point it’s already more likely that your password is compromised via a keylogger or similar than anything else.
Even in English, a language that typically uses short words, your method requires ~30 characters per password.
I’ll accept this as a downside of the method, but honestly a website that limits your password character length to under 30 is probably doing some other weird shit that isn’t good.
Also, the only time you should really be using this method is if for some reason you don’t want to use a password manager. Not many scenarios like that that also limit characters.
yet the harder to remember
I feel like the exact opposite is true? Pretty easy to remember “defenestrate”. Much easier than remembering which
mturns into a3in your method.The 11 characters password is not the suggestion, but an example,
I’m aware how examples work. It’s 11 characters long and already too hard to remember.
I don’t know how you’re meant to remember that “Works” and “Mighty” are capitalized
Refer to step 1, please: pick a quote that you know by heart. And you’re still confusing the example with what it exemplifies.
At this rate it’s rather clear that you’re unable to parse simple sentences, and can be safely ignored as noise.
pick a quote that you know by heart
so step 1 is actually “learn a long, obscure quote by heart” because obviously it can’t be a common quote or it completely breaks the method, and the only quotes you’re likely to know are common
you’re right this is so easy
you’re still confusing the example with what it exemplifies.
In most other quotes, the only capitalization occurs once at the start, so it doesn’t add any meaningful entropy.
At this rate it’s rather clear that you’re unable to parse simple sentences,
somebody’s a little spicy over the fact that they gave terrible advice :(
Just sharing this link to another comment I made replying to you, since it addresses your calculations regarding entropy: https://ttrpg.network/comment/7142027
Or, like, use bitwarden or something to do it for you.
Don’t get me wrong, password managers are fucking great. But sometimes you need to remember a password. (Including one for Bitwarden itself.)
Being a bit pedantic here, but I doubt this is because they trained their model on the entire internet. More likely they added Reddit and many other sites to an index that can be referenced by the LLM and they don’t have enough safeguards in place. Look up “RAG” (Retrieval-augmented generation) if you want to learn more.
We had a tool that answered all of this for us already and more accurately (most of the time). It was called a search engine. Maybe Google would work on one
people can’t google anymore. it’s actually sad
Somewhat amused that the guy things “UW” universally means “University of Wisconsin”. There are lots of UWs out there, and the AI at least chose the largest (University of Washington), though it did claim that William Taft was class of 2000.
Even for Wisconsin, UW is the system. There’s UW Lacrosse, UW Milwaukee, UW Madison, UW Platteville, UW Whitewater…
…UW Laramie, UW Seattle…
Oh wait.
It’s a big school, I bet he was. But not THAT William Taft.
Some of the answers are questions?











