

2·
6 months agoI don’t know if it’s your cup of tea, but Neovide provides smooth scrolling at arbitrary refresh rates. (It’s a graphical frontend for Neovim, my IDE of choice.)
Programmer in NYC
I don’t know if it’s your cup of tea, but Neovide provides smooth scrolling at arbitrary refresh rates. (It’s a graphical frontend for Neovim, my IDE of choice.)

For the PaperWM fans, this is a dedicated WM based on the same idea
For some more detail see https://dev.to/martiliones/how-i-got-linus-torvalds-in-my-contributors-on-github-3k4g
It looks like there is at least one work-in-pprogress implementation. I found a Hacker News comment that points to github.com/n0-computer/iroh
Yeah, that makes a lot of sense. If the thinking is that AI learning from others’ works is analogous to humans learning from others’ works then the logical conclusion is that AI is an independent creative, non-human entity. And there is precedent that works created by non-humans cannot be copyrighted. (I’m guessing this is what you are thinking, I just wanted to think it out for myself.)
I’ve been thinking about this issue as two opposing viewpoints:
The logic-in-a-vacuum viewpoint says that AI learning from others’ works is analogous to humans learning from others works. If one is not restricted by copyright, neither should the other be.
The pragmatic viewpoint says that AI imperils human creators, and it’s beneficial to society to put restrictions on its use.
I think historically that kind of pragmatic viewpoint has been steamrolled by the utility of a new technology. But maybe if AI work is not copyrightable that could help somewhat to mitigate screwing people over.
That sounds like a good learning project to me. I think there are two approaches you might take: web scraping, or an API client.
My guess is that web scraping might be easier for getting started because scrapers are easy to set up, and you can find very good documentation. In that case I think Perl is a reasonable choice of language since you’re familiar with it, and I believe it has good scraping libraries. Personally I would go with Typescript since I’m familiar with it, it’s not hard (relatively speaking) to get started with, and I find static type checking helpful for guiding one to a correctly working program.
OTOH if you opt to make a Lemmy API client I think the best language choices are Typescript or Rust because that’s what Lemmy is written in. So you can import the existing API client code. Much as I love Rust, it has a steeper learning curve so I would suggest going with Typescript. The main difficulty with this option is that you might not find much documentation on how to write a custom Lemmy client.
Whatever you choose I find it very helpful to set up LSP integration in vim for whatever language you use, especially if you’re using a statically type-checked language. I’ll be a snob for just a second and say that now that programming support has generally moved to the portable LSP model the difference between vim+LSP and an IDE is that the IDE has a worse editor and a worse integrated terminal.
I pretty much always use list/iterator combinators (map, filter, flat_map, reduce), or recursion. I guess the choice is whether it is convenient to model the problem as an iterator. I think both options are safer than for loops because you avoid mutable variables.
In nearly every case the performance difference between the strategies doesn’t matter. If it does matter you can always change it once you’ve identified your bottlenecks through profiling. But if your language implements optimizations like tail call elimination to avoid stack build-up, or stream fusion / lazy iterators then you might not see performance benefits from a for loop anyway.
PaperWM has columns - you can move multiple windows into a column (Super+I by default, or Super+O to move a window out of a column). When you move windows left or right or resize horizontally the column moves or resizes as a group. That’s the only feature that groups windows.
I mention Niri because I’m interested to see more implementations of the same idea. The only other scrolling window manager I know of is CardboardWM which is long dead. A native implementation like Niri might be able to explore ideas that are difficult to implement in an extension.
I’ve been using this for maybe a couple of years, and I love it! I like that windows stay at the sizes I set them to, and at the same time I can put as many windows in a workspace as I want.
PaperWM is not bug-free, but an active dev community has grown around it, and they do a lot of work to keep it running as smoothly as possible. That includes the essential task of working around breaking extension API changes when new Gnome releases are coming.
I’ve also been keeping an eye on Niri which applies the same idea to a standalone window manager. I haven’t switched because Niri doesn’t currently implement XWayland. But it looks like Wine is getting closer to native Wayland support so XWayland might not be a requirement for me for much longer.
And there is also Nushell and similar projects. Nushell has a concept with the same purpose as jc where you can install Nushell frontend functions for familiar commands such that the frontends parse output into a structured format, and you also get Nushell auto-completions as part of the package. Some of those frontends are included by default.
As an example if you run ps you get output as a Nushell table where you can select columns, filter rows, etc. Or you can run ^ps to bypass the Nushell frontend and get the old output format.
Of course the trade-off is that Nushell wants to be your whole shell while jc drops into an existing shell.
I’m a fan! I don’t necessarily learn more than I would watching and reading at home. The main value for me is socializing and networking. Also I usually learn about some things I wouldn’t have sought out myself, but which are often interesting.
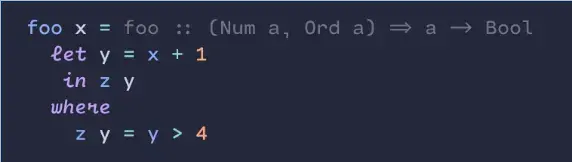
That’s a very nice one! I also enjoy programming ligatures.
I use Cartograph CF. I like to use the handwriting style for built-in keywords. Those are common enough that I identify them by shape. The loopy handwriting helps me to skim over the keywords to focus on the words that are specific to each piece of code.
I wish more monospace fonts would use the “m” style from Ubuntu Mono. The middle leg is shortened which makes the glyph look less crowded.

It looks like a useful tool - thanks for sharing all of that info! Personally I would prefer to set up a shell alias or wrapper script for each command I want to run in distrobox instead of using a missing-program hook.
git rebase --onto is great for stacked branches when you are merging each branch using squash & merge or rebase & merge.
By “stacked branches” I mean creating a branch off of another branch, as opposed to starting all branches from main.
For example imagine you create branch A with multiple commits, and submit a pull request for it. While you are waiting for reviews and CI checks you get onto the next piece of work - but the next task builds on changes from branch A so you create branch B off of A. Eventually branch A is merged to main via squash and merge. Now main has the changes from A, but from git’s perspective main has diverged from B. The squash & merge created a new commit so git doesn’t see it as the same history as the original commits from A that you still have in B’s branch history. You want to bring B up to date with main so you can open a PR for B.
The simplest option is to git merge main into B. But you might end up resolving merge conflicts that you don’t have to. (Edit: This happens if B changes some of the same lines that were previously changed in A.)
Since the files in main are now in the same as state as they were at the start of B’s history you can replay only the commits from B onto main, and get a conflict-free rebase (assuming there are no conflicting changes in main from some other merge). Like this:
$ git rebase --onto main A B
The range A B specifies which commits to replay: not everything after the common ancestor between B and main, only the commits in B that come after A.
Just a guess: I think Inform fits your description
Steam Decks run Linux. (The specific DE is KDE Plasma I think.) So you can find answers by searching for “Linux” if searching for “Steam Deck” doesn’t get results.
One way is to enable the “Compose” key which lets you enter special characters or sequences by typing switches of more commonly-available characters. I think the Steamdeck OS has a setting for this; but I don’t have one so I can’t check.
For letters with umlauts you press (and release) Compose, then type a double quote (need to hold shift for this part), then type a vowel.
For reference Wikipedia has a list of Common Compose Combinations
Alternatively if you can map an AltGr key I’ve read you can type umlauts by typing AltGr+[ and then typing a vowel. There might be a setting for this too.
Oh, very nice! Thanks for letting me know
I built a wireless Corne keyboard from a kit. It uses nice!nano controllers running ZMK. Previously when I used a Kinesis Advantage 2 I replaced its controller board with a KinT which uses a Teensy as its controller. Customizing the keyboard with custom firmware is much nicer than customizing in the OS. But it can be a commitment. Although there are some keyboards that come the reprogramming options out-of-the-box, like the Kinesis Advantage 360, the Moonlander, all of Keyboardio’s models.
The default Gnome installation on NixOS uses Wayland. And GDM too - it’s pretty much the same as other distros I’ve used. I’d guess the Plasma install option is also on Wayland.
I do have some issues with screen sharing. It generally works fine in Firefox and Discord. But screen sharing in Slack crashes every time.

It scrolls smoothly, it doesn’t snap line by line. Although once the scroll animation is complete the final positions of lines and columns do end up aligned to a grid.
Neovim (as opposed to Vim) is not limited to terminal rendering. It’s designed to be a UI-agnostic backend. It happens that the default frontend runs in a terminal.