

3 days ago I setup fail2ban. Nothing fancy, just reading the logs of my docker containers where it applied.
Then 2 days ago my server crashed out of nowhere, nothing in the f2b logs (I thought I had banned the entire internet by mistake), doing a nap just tells me port 80 and 443 were open (a few more should have been for Plex).
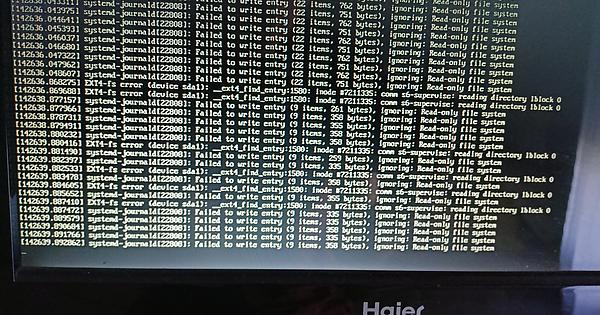
The same happened yesterday and I pulled the cable just in case I was being hacked (I’m paranoid but not too much), and looked in it. usually I ssh from my local network into the server, but couldn’t this time, so I put a screen on it and it was quickly flooded with systemd failures and ext4 errors.
I reformated the disk a few months ago and ran a SMART, it told me the disk was fine, no error detected. It is a chonky 2TB disk and I have at most 150gigs used (movies, music, backups waiting to be transferred on daily basis to other servers/media, dockers).
Where should I look? I know how to work with Linux but when looking for a problem like this, except using systemctl status/restart I’m lost.
Did you run a short or long SMART test? How old is the drive? Usually those errors are the beginnings a failing drive in my experience unless you are doing mass I/O (like TB/s) and it can’t update the filesystem meta fast enough for some reason.
Short SMART test, the drive is 5 years old at most. The most I’m doing on the drive is MB/s… So it should be fine
I’ll try to get a new drive, probably SSD. Can it be related to the drives card? I have an hardware RAID drive aggregator card, with a single disk on it (had 3 in the past and the 2 oldest ones just died at the same time, making scratching noises ; they were 10+ years old but SMART said everything is fine (short one, haven’t tried a long one as smartctl -a tells me it will take about 5-10 for all disks).
Yeah the long test does a surface inspection and checks all of the sectors so it will take a while, you can run it in the background though and it might default to that.
Do backup important data though as if it is in fact failing the extra I/O might tip it over the edge, can’t be too careful.
If it was me, I would probably run fsck and reboot the first time in case it was a fluke and then investigate the drive if it happens repeatedly.
If you are worried about it’s age, the SMART will also tell you the power on hours of the drive, that’s the age that matters (well, and TB written sometimes). Each manufacturer has different mean time between failure ratings depending on the type of drive as well, you can also check backblaze data sometimes.
Hope that helps!